Software Support SLAs: Response Times, Escalation Paths, and Ownership
A support SLA is not just a response-time promise. It is the operating agreement that decides who gets pulled in, how incidents escalate, and what your product team is actually paying for.
Jason Overmier
Innovative Prospects Team
Most support arrangements fail because everyone thinks they bought the same thing when they did not.
A founder expects a critical outage to get immediate attention. The engineering partner assumes “support” means next-business-day investigation. A support lead escalates into a void because no one documented who can approve a rollback. None of that is a technical problem. It is an SLA problem.
What an SLA Should Actually Define
| Area | What should be explicit |
|---|---|
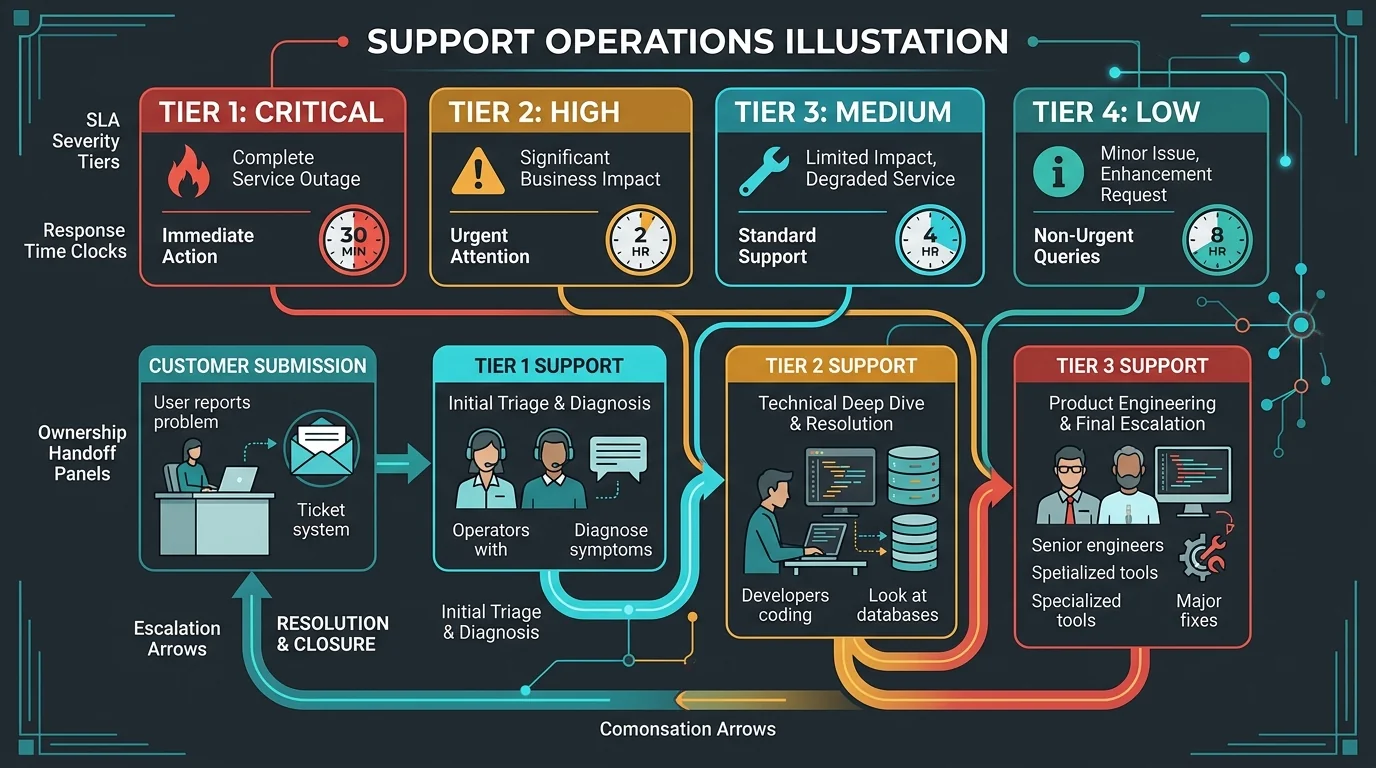
| Severity levels | What counts as P1, P2, and P3 |
| Response time | How fast triage begins |
| Update cadence | How often stakeholders hear from you during incidents |
| Escalation path | Who gets paged next if the issue is unresolved |
| Scope | Which systems and environments are covered |
If those details are vague, “24/7 support” is mostly marketing language.
Severity Definitions Drive Everything
| Severity | Example | Expected behavior |
|---|---|---|
| P1 | Revenue-impacting outage or security event | Immediate response and active coordination |
| P2 | Major degradation with no clean workaround | Same-day triage and owner assignment |
| P3 | Limited issue with workaround | Scheduled response in normal operating hours |
The mistake is not choosing the wrong response time. The mistake is failing to match response time to business risk.
Escalation Paths Matter More Than the Contract PDF
During a real incident, teams need to know:
- who can declare severity
- who owns communication
- who can approve mitigations or rollbacks
- which vendors or infrastructure owners may need to be pulled in
- when leadership gets notified
If escalation still depends on memory, the support model is brittle before the incident even starts.
What Good Runbooks Support
Every covered system should have a short runbook for:
- restarting or failing over safely
- validating whether the problem is real or noisy alerting
- rolling back recent changes
- rotating credentials or isolating access if needed
- contacting the next escalation point quickly
Runbooks do not replace judgment. They reduce wasted time before judgment starts.
Common Pitfalls
| Pitfall | Why It Happens | Fix |
|---|---|---|
| Severity levels are too vague | Nobody wanted hard boundaries | Use concrete business examples |
| Response times are promised without staffing | Sales language outran delivery reality | Match SLA promises to actual coverage |
| Escalation path ends with one heroic engineer | Ownership is centralized informally | Name backups and decision-makers |
| Runbooks exist but are stale | Nobody updates them after incidents | Revise them as part of postmortem follow-up |
The Better Buying Question
Instead of asking “Do we have support?” ask:
- What systems are actually covered?
- What triggers immediate response?
- Who gets involved at each severity?
- What does the team need from us to resolve incidents quickly?
Those answers reveal far more than a monthly retainer number.
If you need a clearer support model for a live product, get in touch. We help teams define practical SLAs, escalation paths, and operational ownership before the next incident tests them.