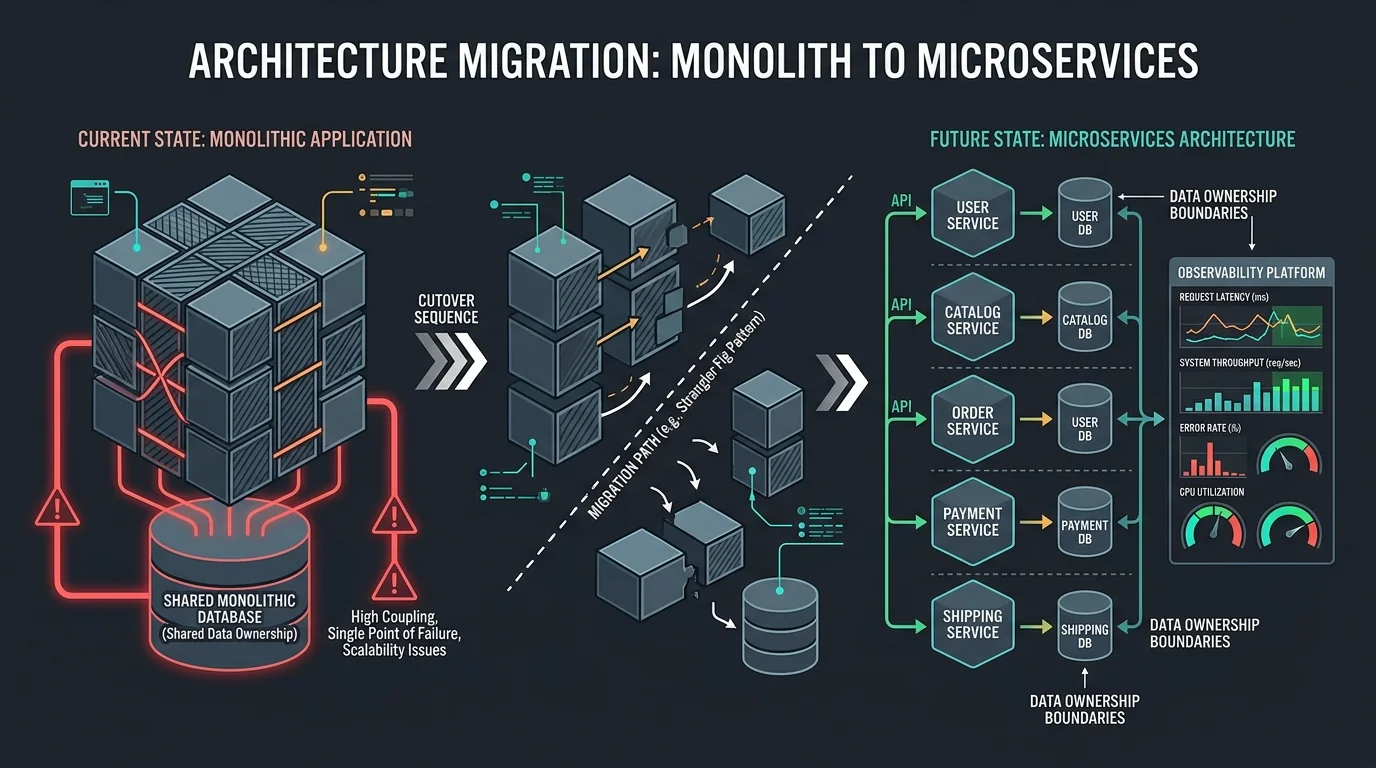
Monolith to Microservices Migration: Sequence, Data Ownership, and Cutover Risk
Once you've decided to extract services, the real work starts. Migration success depends less on diagrams and more on sequencing, ownership, and cutover discipline.
Jason Overmier
Innovative Prospects Team
Most monolith-to-microservices projects fail after the architecture decision has already been made. The team agrees to extract services, then underestimates data ownership, release sequencing, and the operational cost of running the result.
If you are still deciding whether to split at all, start with Monolith vs Microservices. This article assumes you have already made that call and need a safer migration path.
Quick Answer
Successful migrations usually share four traits:
- one service boundary is chosen first, not five
- data ownership is explicit before code moves
- rollback paths are designed before cutover
- observability is improved before traffic is split
What to Extract First
Start with a boundary that is both important and understandable.
Good first candidates:
- Asynchronous jobs and workers
- Notification systems
- Search and indexing
- Reporting pipelines
- File processing
Bad first candidates:
- Shared auth logic used everywhere
- Cross-cutting data models
- Anything whose business rules are still changing weekly
A Safer Migration Sequence
| Step | Outcome |
|---|---|
| 1. Pick one domain | A service candidate with a clear owner |
| 2. Define ownership rules | No ambiguity about who owns data and APIs |
| 3. Separate read paths | Lower-risk validation before write cutovers |
| 4. Add observability | Better debugging before new failure modes appear |
| 5. Migrate write paths | Clear consistency and rollback decisions |
| 6. Retire old paths | No permanent dual-system drift |
The goal is not to create services quickly. The goal is to create one service the team can operate confidently.
Data Consistency Is the Real Work
Most migration plans focus on code boundaries. The harder problem is data.
Before extraction, answer these questions:
- Which system owns the record?
- What happens if a downstream update fails?
- Which data must be strongly consistent?
- What can become eventually consistent?
- How will support teams debug cross-service failures?
If those answers are fuzzy, you are not ready to extract the service yet.
Cutover Strategy Matters More Than the Diagram
Teams often spend too much time debating sync versus async architecture and not enough time on cutover mechanics.
Good migration plans define:
- what traffic moves first
- what telemetry confirms the new path is healthy
- when rollback is triggered
- how long dual-write or parallel-read modes will exist
Without those rules, the migration drags out and the old system never really dies.
Team Coordination Matters More Than YAML
Microservices only help when ownership gets clearer.
| Question | Healthy Answer |
|---|---|
| Who deploys this service? | One clear team |
| Who gets paged for failures? | The same team |
| Who approves breaking changes? | The service owner plus consumers |
| Where is the contract documented? | In versioned code and tests |
If ownership still flows through one platform lead for every change, you have a distributed monolith.
Common Pitfalls
| Pitfall | Why It Happens | Fix |
|---|---|---|
| Shared database survives forever | Extraction stopped at the API layer | Assign data ownership per service |
| Too many services too early | Leadership wants visible progress | Limit the first wave to one or two domains |
| Dual-write lasts indefinitely | The team never defines an exit condition | Add explicit retirement milestones |
| Latency spikes | Synchronous service chains replace local calls | Prefer async workflows where possible |
| Debugging becomes harder | No tracing or correlation IDs | Invest in observability before expansion |
What Good Looks Like
A healthy first migration usually ends with:
- one service with clear runtime ownership
- one data boundary that no longer depends on the monolith database
- one deployment path the team can roll back cleanly
- enough monitoring to explain failures quickly
That is slower on architecture diagrams and faster in production.
If you are deciding whether to split a monolith or keep tightening it up, reach out. We help teams map service boundaries, migration order, and the operational cost before they commit to a rewrite.